
Head vs breakz
[인공지능]- One shot learning with Siamese Networks using keras - Harshall lamba - 2 본문
[인공지능]- One shot learning with Siamese Networks using keras - Harshall lamba - 2
headbreakz 2020. 2. 28. 12:09One shot learning with Siamese Networks using keras - Harshall lamba
https://towardsdatascience.com/one-shot-learning-with-siamese-networks-using-keras-17f34e75bb3d
를 공부하기 위해 번역과 정리 하는 글입니다.
Model Architecture and Training
이 코드는 Gregory Koch et al. 의 research paper에 나와있는 방법론을 구현하였다. 모델의 구조와 하이퍼파라미터 값은 논문에 있는 값을 사용하였다.
구조를 먼저 들어다 본다면,
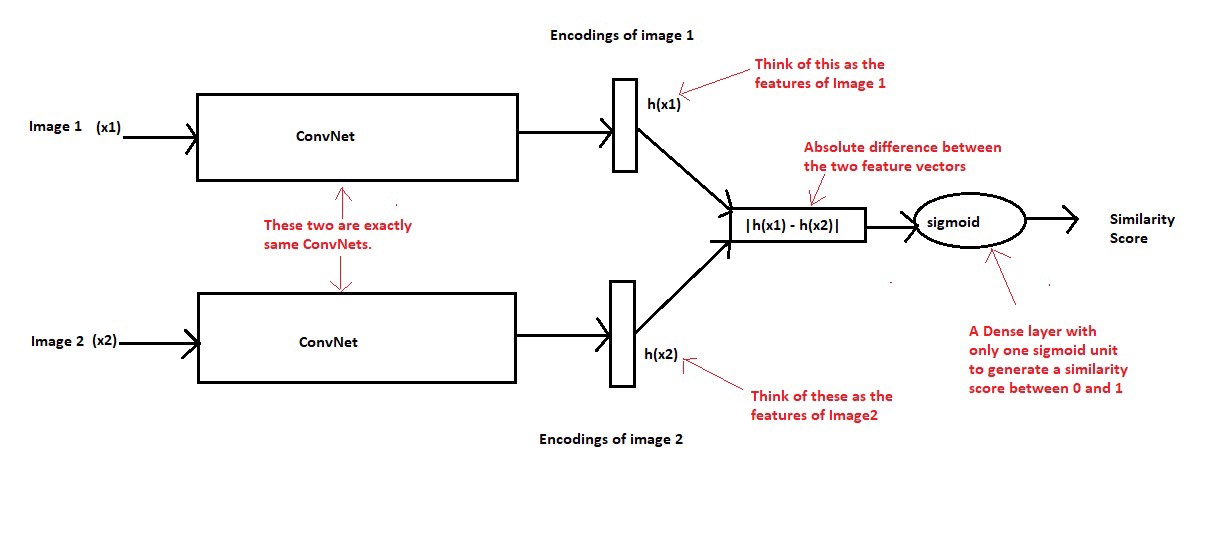
Convolutional Neural Networks는 다른 네트워크가 아닌 동일한 네트워크이다. 매개 변수 값을 공유한다. x1과 x2 두개의 이미지가 ConvNet을 지나 각각의 fixed length feature vector를 생성한다. neural network 모델이 훈련이 잘되어 있다고 가정한다면, 두개의 입력 이미지가 같은 문자라면 feature vectors 또한 비슷하다. 두개의 이미지가 다른 문자라면 feature vectors 는 차이가 있다. 그래서 두 이미지의 feature vectors는 위와 같은 경우에 분명히 차이가 있어야하며, sigmoid layer층에서 생성된 유사성 점수도 차이가 있어야한다.
논문에 나와 있는 세부 구조를 본다면,
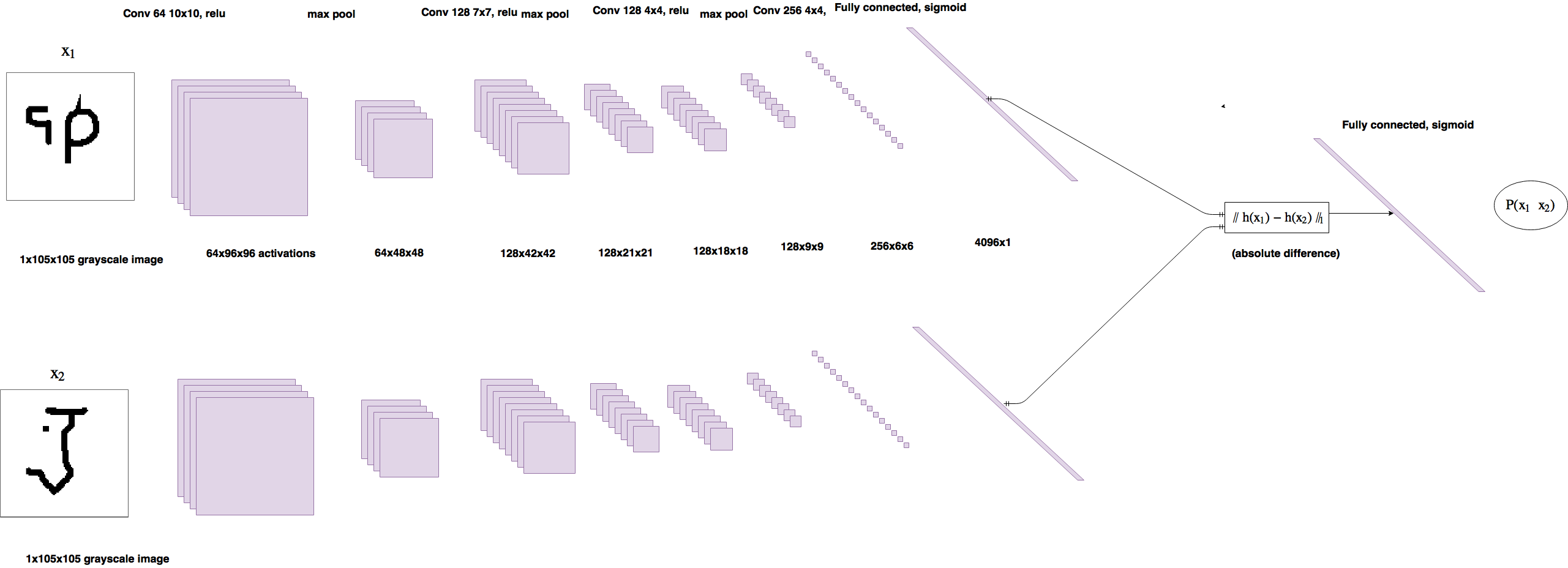
Image Source: https://www.cs.cmu.edu/~rsalakhu/papers/oneshot1.pdf
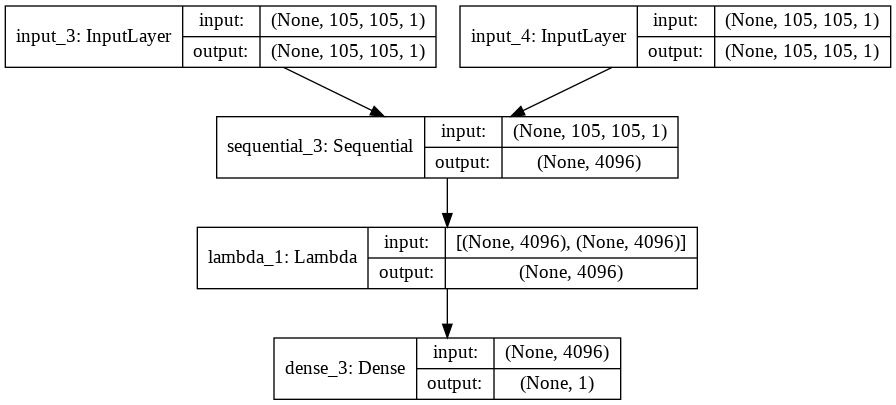
- 모델 아키텍쳐를 만드는 코드
def get_siamese_model(input_shape):
"""
Model architecture
"""
# Define the tensors for the two input images
left_input = Input(input_shape)
right_input = Input(input_shape)
# Convolutional Neural Network
model = Sequential()
model.add(Conv2D(64, (10,10), activation='relu', input_shape=input_shape,
kernel_initializer=initialize_weights, kernel_regularizer=l2(2e-4)))
model.add(MaxPooling2D())
model.add(Conv2D(128, (7,7), activation='relu',
kernel_initializer=initialize_weights,
bias_initializer=initialize_bias, kernel_regularizer=l2(2e-4)))
model.add(MaxPooling2D())
model.add(Conv2D(128, (4,4), activation='relu', kernel_initializer=initialize_weights,
bias_initializer=initialize_bias, kernel_regularizer=l2(2e-4)))
model.add(MaxPooling2D())
model.add(Conv2D(256, (4,4), activation='relu', kernel_initializer=initialize_weights,
bias_initializer=initialize_bias, kernel_regularizer=l2(2e-4)))
model.add(Flatten())
model.add(Dense(4096, activation='sigmoid',
kernel_regularizer=l2(1e-3),
kernel_initializer=initialize_weights,bias_initializer=initialize_bias))
# Generate the encodings (feature vectors) for the two images
encoded_l = model(left_input)
encoded_r = model(right_input)
# Add a customized layer to compute the absolute difference between the encodings
L1_layer = Lambda(lambda tensors:K.abs(tensors[0] - tensors[1]))
L1_distance = L1_layer([encoded_l, encoded_r])
# Add a dense layer with a sigmoid unit to generate the similarity score
prediction = Dense(1,activation='sigmoid',bias_initializer=initialize_bias)(L1_distance)
# Connect the inputs with the outputs
siamese_net = Model(inputs=[left_input,right_input],outputs=prediction)
# return the model
return siamese_netkeras에는 두 tensors 같의 절대값 차이를 예측하는 layer가 없다. 그래서 Keras의 customized layers층을 통해 Lambda layer층으로 생성하여 사용한다.
이 모델은 adam optimizer과 binary cross entropy loss function를 사용하였고, 학습율을 낮게 유지하였다.
optimizer = Adam(lr = 0.00006)
model.compile(loss="binary_crossentropy",optimizer=optimizer)batch_size를 32로 20000회 반복하여 훈련시켰고, 200회 마다 20번의 one shot learning을 하였다. 그리고 250회 이상에서 정확도를 측정하였다.
Validating the Model
모델을 테스트하고 검증하는 전략을 생각해보자
모든 이미지 쌍에 대해 0과1사이의 유사성 점수를 생성하지만 모델이 실제로 비슷한지 안비슷한지에 대해 알고 있는지 확인하기 어렵다. 그래서 이점을 판단하기 위해서 N-way one shot learning 을 사용한다.
- 4 way one shot learning
다음과 같이 4쌍의 이미지 쌍을 준비한다.

동일한 문자는 4개의 다른 문자와 비교되고 그중 한개만 원본과 일치한다. 4개의 문자를 비교하면 4개의 유사성 점수를 얻을 수 있다.(S1,S2,S3,S4) 이 모델이 잘 학습된 모델이라면 S1의 유사성 점수가 가장 높게 나타날 것이다.
따라서 S1이 가장 높은 점수로 나타난다면, 정확한 판단으로 간주하고, 그렇지 않으면 잘못된 판단으로 간주한다. 이 절차를 K 번 반복하면 정확한 예측의 백분율을 계산할 수 있다.
percent_correct = (100 * n_correct) / k
where k => total no. of trials and n_correct => no. of correct predictions out of k trials.N-way one shot learning에서 N은 완벽한 제곱일 필요는 없다. N의 값이 작을 수록 더욱 정확한 예측이 가능해지고, N의 값이 클수록 반복 될수록 상대적으로 덜 정확한 예측이 된다.
- support set에 속하는 테스트 이미지를 생성하는 코드
def make_oneshot_task(N, s="val", language=None):
"""Create pairs of test image, support set for testing N way one-shot learning. """
if s == 'train':
X = Xtrain
categories = train_classes
else:
X = Xval
categories = val_classes
n_classes, n_examples, w, h = X.shape
indices = rng.randint(0, n_examples,size=(N,))
if language is not None: # if language is specified, select characters for that language
low, high = categories[language]
if N > high - low:
raise ValueError("This language ({}) has less than {} letters".format(language, N))
categories = rng.choice(range(low,high),size=(N,),replace=False)
else: # if no language specified just pick a bunch of random letters
categories = rng.choice(range(n_classes),size=(N,),replace=False)
true_category = categories[0]
ex1, ex2 = rng.choice(n_examples,replace=False,size=(2,))
test_image = np.asarray([X[true_category,ex1,:,:]]*N).reshape(N, w, h,1)
support_set = X[categories,indices,:,:]
support_set[0,:,:] = X[true_category,ex2]
support_set = support_set.reshape(N, w, h,1)
targets = np.zeros((N,))
targets[0] = 1
targets, test_image, support_set = shuffle(targets, test_image, support_set)
pairs = [test_image,support_set]
return pairs, targets
def test_oneshot(model, N, k, s = "val", verbose = 0):
"""Test average N way oneshot learning accuracy of a siamese neural net over k one-shot tasks"""
n_correct = 0
if verbose:
print("Evaluating model on {} random {} way one-shot learning tasks ... \n".format(k,N))
for i in range(k):
inputs, targets = make_oneshot_task(N,s)
probs = model.predict(inputs)
if np.argmax(probs) == np.argmax(targets):
n_correct+=1
percent_correct = (100.0 * n_correct / k)
if verbose:
print("Got an average of {}% {} way one-shot learning accuracy \n".format(percent_correct,N))
return percent_correct'Head > 인공지능' 카테고리의 다른 글
| [인공지능] - Gradient Clipping (0) | 2020.03.24 |
|---|---|
| [인공지능]- One shot learning with Siamese Networks using keras - Harshall lamba - 3 (0) | 2020.02.29 |
| [인공지능] - One shot learning with Siamese Networks using keras - Harshall lamba - 1 (0) | 2020.02.27 |
| [인공지능] - the Neural Network zoo (0) | 2020.02.20 |
| [인공지능] - Hyperopt (0) | 2020.02.19 |



